
Данные понятие типы данных шпора
Данные. Алгоритм, реализующий решение некоторой конкретной задачи, всегда работает с данными. Данные — это любая информация, представленная в формализованном виде и пригодная для обработки алгоритмом.
Данные, известные перед выполнением алгоритма, являются начальными, исходными данными. Результат решения задачи — это конечные, выходные данные. В задачах нахождения максимума из последовательности чисел и их произведения исходными данными являются числа, а результатами (выходными данными) — соответственно с и М.
Данные делятся на переменные и константы.
Переменные — это такие данные, значения которых могут изменяться в процессе выполнения алгоритма.
Например, для алгоритма вычисления площади круга необходимо объявить две переменные: переменную R, в которую будет заноситься значение радиуса окружности, и переменную S для вычисления площади круга по формуле
Константы — это данные, значения которых не меняются в процессе выполнения алгоритма. В примере, описанном выше, константой является число к. Каждая переменная и константа должна иметь свое уникальное имя. Имена переменных и констант задаются идентификаторами.
Идентификатор (по определению) представляет собой последовательность букв и цифр, начинающаяся с буквы.
Типы данных. С данными тесно связано понятие типа данных. Любой константе, переменной, выражению (с точки зрения обработки на ЭВМ) всегда сопоставляется некоторый тип. Тип данных характеризует множество значений, к которым относится константа и которые может принимать переменная или выражение. Например, если переменная в некотором алгоритме может принимать только значения из множества целых чисел, то ей ставится в соответствие целый тип данных.
Типы данных принято делить на простые (базовые) и структурированные.
К основным базовым типам относятся:
• целый (INTEGER) — определяет подмножество допустимых значений из множества целых чисел;
• вещественный (REAL) — определяет подмножество допустимых значений из множества вещественных чисел;
• логический (BOOLEAN) — множество допустимых значений — истина и ложь;
• символьный (CHAR) — цифры, буквы, знаки препинания и пр.
Тип INTEGER задает подмножество целых чисел, мощность которого зависит от такой характеристики ЭВМ, как размер машинного слова. Если для представления целых чисел в машине используется п разрядов (причем один из них отводится под указание знака числа), то допустимые числа должны удовлетворять условию -2 n-1 2 n -1 . Считается, что все операции над данными этого типа выполняются точно и соответствуют обычным правилам арифметики. Если результат выходит за пределы допустимых значений, то вычисления будут прерваны. Такое событие называется переполнением. Четыре арифметические операции считаются стандартными: сложение (+), вычитание (-), умножение (*) и деление (/). Для целых чисел может быть определен дополнительный стандартный тип — целое без знака, задающий подмножество целых положительных чисел. Если для представления целых без знака используется п разрядов, то переменным такого типа можно присваивать значения, удовлетворяющие условию
Тип REAL обозначает подмножество вещественных чисел, границы, изменения которых также определяются характеристиками конкретной ЭВМ. И если считается, что арифметика с данными типа INTEGER дает точный результат, то допускается, что аналогичные действия со значениями типа REAL могут быть неточными, в пределах ошибок округлений, вызванных вычислениями с конечным числом цифр. Это принципиальное различие между типами REAL и INTEGER. Два значения базового типа BOOLEAN обозначаются идентификаторами TRUE FALSE. В базовый тип CHAR входит множество печатаемых символов и символов-разделителей в соответствии с кодом ASCII.
Приведем пример представления числовой информации в различных типах данных применительно к ЭВМ с 16-разрядным машинным словом.
Пусть задано число 12345.
Таким образом, тип данных — это такая характеристика данных, которая, с одной стороны, задает множество значений для возможного изменения данных и, с другой стороны, определяет множество операций, которые можно к этим данным применять, и правила выполнения этих операций. До сих пор мы говорили о переменных, хранящих только одно значение, и рассматривали возможности различного представления и использования этого значения при решении конкретных задач. На самом деле, огромное количество алгоритмов требует одновременного хранения в памяти целых наборов однородных объектов, причем длина этих наборов может быть заранее неизвестна. Например, пусть необходимо обрабатывать данные о среднесуточной температуре за год для вычисления максимальной и минимальной температур, среднемесячной и среднегодовой температуры и т.п. Для реализации таких алгоритмов необходимо обеспечить хранение каждого отдельного значения среднесуточной температуры. Если иметь при этом в виду переменные базового типа Real, то таких переменных потребовалось бы 365.
Структурированные типы описывают наборы однотипных или разнотипных данных, с которыми алгоритм должен работать как с одной именованной переменной.
Массив. Наиболее широко известная структура данных — массив. Массив представляет собой упорядоченную структуру однотипных данных, которые называются элементами массива. Структура данных типа массив подходит, например, для решения задачи обработки среднесуточных температур, описанной выше. Доступ к каждому отдельному элементу массива осуществляется с помощью индекса — в общем случае порядкового номера элемента в массиве. Массивы могут быть как одномерными (адрес каждого элемента определяется значением одного индекса), так и многомерными (адрес каждого элемента определяется значением нескольких индексов). Рассмотрим задачу сортировки (расположения) по возрастанию N целых чисел. Для ее решения, во-первых, необходимо обеспечить ввод всех N чисел, а затем применить один из известных методов сортировки. Любой метод сортировки предполагает неоднократный проход всех или части чисел, поэтому числа целесообразно организовать в массив.

Рис. 4. Сортировка массива из 5 элементов
Метод сортировки посредством простого выбора предполагает циклический просмотр элементов массива, начиная с i-го (i= 1,2. N— 1), поиск минимального элемента и перестановку найденного минимального элемента с i-м. За N — 1 проход по массиву (элемент с номером N останется на своем месте) числа будут отсортированы (рис. 1.4).
Подобный алгоритм, очевидно, состоит из трех этапов:
• ввод элементов массива;
• цикл обработки массива;
• вывод отсортированных чисел из массива.
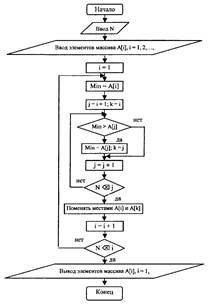
Рис. 5. Блок-схема алгоритма сортировки элементов массива по возрастанию
z типа Complex — объект, описывающий комплексное число, с полями re и im типа Real;
d типа Date — объект, описывающий дату, с полями day, month и year со значениями из подмножеств типа Integer (например, day может быть целым числом в интервале от 1 до 31);
Таблица 1.2. Типы и структуры данных в некоторых языках
| | | следующая лекция ==> | |
| Примеры и решения. 1.Рассмотрим следующую известную задачу: имеются два кувшина емкостью 3 и 8 л | | | Примеры и решения |
Нам важно ваше мнение! Был ли полезен опубликованный материал? Да | Нет
Информация, поступающая в компьютер, состоит из определенного множества данных, относящихся к какой-то проблеме, — это именно те данные, которые относятся к конкретной задаче и из которых требуется получить желаемый ответ. В математике классифицируют данные в соответствии с некоторыми важными характеристиками. Принято различать целые, вещественные и логические данные, множества, последовательности, векторы, матрицы (таблицы) и т.д. В обработке данных на компьютере классификация играет даже боRльшую роль.
Любая константа, переменная, выражение или функция относятся к некоторому типу. Тип данных определяет диапазон допустимых значений и операций, которые могут быть применены к этим значениям. Кроме того, тип данных задает формат представления объектов в памяти компьютера, ведь в конце концов любые данные будут представлены в виде последовательности двоичных цифр (нулей и единиц). Тип данных указывает, каким образом следует интерпретировать эту информацию. Тип любой величины может быть установлен при ее описании, а в некоторых языках может выводиться компилятором по ее виду (Fortran, Basic).
Например, если переменная имеет целочисленный тип данных, то таким образом определен диапазон значений, которые могут быть сохранены в этой переменной (целые числа) и определены операции, которые могут быть применены к этой переменной (арифметические, логические, возможность ввода и вывода значений этой переменной). Каждый язык программирования поддерживает один или несколько типов данных. Наличие в языке программирования типизации означает жесткую связку операций и типов объектов, над которыми их можно выполнять. Не все языки обладают таким свойством. Например, в языке С практически любые операции можно выполнять над любыми данными (например, складывать два символа или число с логическим значением, но в большинстве случаев такие операции бессмысленны и соответствуют ошибке в программе, на которую компилятор указать не сможет).
Любые данные могут быть отнесены к одному из двух типов: простому (основному), форма представления которого определяется архитектурой ЭВМ, или сложному, конструируемому пользователем для решения конкретных задач. Данные простого типа — это символы, числа и т.п. элементы, дальнейшее дробление которых не имеет смысла. Из таких элементарных данных формируются структуры (сложные типы) данных.
Принято различать следующие типы данных:
Рассмотрим перечисленные типы данных подробнее.
Числовые типы. Значениями переменных таких типов являются числа. К ним могут применяться обычные арифметические операции, операции сравнения (в результате получается логическое значение). Принципиально различны в компьютерном представлении целые и вещественные типы.
Целочисленные типы данных делятся, в свою очередь, на знаковые и беззнаковые. Целочисленные со знаком могут принимать как положительные, так и отрицательные значения, а беззнаковые — только неотрицательные значения. Диапазон значений при этом определяется количеством разрядов, отводимых на представление конкретного типа в памяти компьютера (см. “Представление чисел”).
Символьный тип. Элемент этого типа хранит один символ. При этом могут использоваться различные кодировки, которые определяют, какому коду (двоичному числу) какой символ (знак) соответствует. К значениям этого типа могут применяться операции сравнения (в результате получается логическое значение). Символы считаются упорядоченными согласно своим кодам (номерам в кодовой таблице).
Логический тип. Данные этого типа имеют два значения: истина (true) и ложь (false). К ним могут применяться логические операции. Используется в условных выражениях, операторах ветвления и циклах. В некоторых языках, например С, является подтипом числового типа, при этом ложь = 0, истина = 1 (или истинным считается любое значение, отличное от нуля).
Перечислимый тип. Отражает самый прямолинейный способ описания простого типа — перечисление всех значений, относящихся к этому типу. Каждая константа такого типа получает свой порядковый номер, что позволяет реализовать ряд простых операций над этим типом, таких, как получить следующее по порядку значение данного типа.
Множество как тип данных в основном совпадает с обычным математическим понятием множества. Допустимы стандартные операции с множествами и проверка на принадлежность элемента множеству. В некоторых языках рассматривается как составной тип (массив логических значений, i-й элемент которого указывает, находится ли i в множестве), однако эффективней реализовывать множество как машинное слово (или несколько слов), каждый бит которого характеризует наличие соответствующего элемента в множестве.
Указатель (тип данных). Если описанные выше типы данных представляли какие-либо объекты реального мира, то указатели представляют объекты компьютерного мира, то есть являются исключительно компьютерными терминами. Переменная-указатель хранит адрес в памяти компьютера, указывающий на какую-либо информацию, как правило — на другую переменную.
Составные типы формируются на основе комбинаций простых типов.
Массив является индексированным набором элементов одного типа, простого или составного (см. “Операции с массивами”). Одномерный массив предназначен для компьютерной реализации такой структуры, как вектор, двухмерный массив — таблицы.
Строковый тип. Хранит строку символов. Вообще говоря, может рассматриваться как массив символов, но иногда рассматривается в качестве простого типа. Часто используется для хранения фамилий людей, названий предметов и т.п. К элементам этого типа может применяться операция конкатенации (сложения) строк. Обычно реализованы также операции сравнения над строками, в том числе операции “ ”, которые интерпретируются как сравнение строк согласно алфавитному порядку (алфавитом здесь является набор символов соответствующей кодовой таблицы). Во многих языках реализованы и специальные операции над строками: поиск заданного символа (подстроки), вставка символа, удаление символа, замена символа.
Запись. Наиболее общий метод получения составных типов из простых заключается в объединении элементов произвольных типов. Причем сами эти элементы могут быть, в свою очередь, составными. Так, человек описывается с помощью нескольких различных характеристик, таких, как имя, фамилия, дата рождения, пол, и т.д. Записью (в языке С — структурой) называется набор различных элементов (полей записи), хранимый как единое целое. При этом возможен доступ к отдельным полям записи. К полю записи применимы те же операции, что и к базовому типу, к которому это поле относится (тип каждого поля указывается при описании записи).
Последовательность. Данный тип можно рассматривать как массив бесконечного размера (память для него может выделяться в процессе выполнения программы по мере роста последовательности). Зачастую такой тип данных обладает лишь последовательным доступом к элементам. Под этим подразумевается, что последовательность просматривается от одного элемента строго к следующему, формируется же она путем добавления элементов в ее конец. В языке Pascal подобному типу соответствуют файловые типы данных.
Типы данных защищают программы по крайней мере от следующих ошибок:
1. Некорректное присваивание. Пусть переменная объявлена как имеющая числовой тип. Тогда попытка присвоить ей символьное или какое-либо другое значение приведет к ошибке еще на этапе компиляции. Такого рода ошибки трудно отследить обычными средствами.
2. Некорректная операция. Типизация позволяет избежать попыток применения выражений вида “Hello world” + 1. Поскольку, как уже говорилось, все переменные в памяти хранятся как наборы битов, то при отсутствии типов подобная операция была выполнима (и могла дать результат вроде “Hello worle”!). С использованием типов такие ошибки отсекаются опять же на этапе компиляции.
3. Некорректная передача параметров в процедуры и функции (см. “Подпрограммы”). Если функция “синус” ожидает, что ей будет передан числовой аргумент, то передача ей в качестве параметра строки “Hello world” может иметь непредсказуемые последствия. При помощи контроля типов такие ошибки также отсекаются на этапе компиляции или приводят к ошибкам выполнения программы, если значения параметра вводятся с клавиатуры или файла.
Кроме того, типы данных позволяют программисту абстрагироваться от машинного представления информации в виде наборов нулей и единиц и строить программы, основываясь на знакомых понятиях, таких, как числа, множества, последовательности, и т.п. В конечном итоге это приводит к получению более надежных программ.
При изучении данной темы самое главное — разделить следующие понятия:
данные — тип данных — абстрактная структура данных — структура данных
Типом данных переменной называют множество значений, которые может принимать эта переменная, и множество операций, которые применимы к этим значениям.
Абстрактная структура данных (см. “Структуры данных”) — это некоторая математическая модель данных (см. выше), включающая различные операции, определенные в рамках этой модели. Для реализации абстрактной структуры в том или ином языке программирования используются структуры, которые представляют собой набор переменных, возможно различных типов данных, объединенных определенным образом. При этом одна и та же абстрактная структура данных может быть реализована через различные структуры языка программирования. Например, такая абстрактная структура данных, как список, может быть реализована с использованием массива, файла или списка динамических переменных. Примеры различных структур данных, реализующих абстрактную структуру граф, приведены в статье “Табличные модели” 2.
Изучение конкретных типов данных производится в процессе рассмотрения определенного языка программирования в курсе информатики. При этом нельзя совсем не касаться таких вопросов, как представление определенного типа данных в памяти компьютера и диапазон значений, которые могут принимать переменные каждого из типов. Рассказывать стоит и о преобразованиях типов, как автоматических, выполняемых компилятором при анализе операции присваивания, например, вещественной переменной целочисленного выражения, так и производимых программистом, например, при переводе текстовой информации в числовую и т.д.
Изучение особенностей представления целых чисел (а именно этот тип данных встречается в учебных задачах по программированию чаще всего) полезно проиллюстрировать следующим примером.
Пример. С помощью программы на языке Borland Pascal вычислим значение n! (факториал числа n). Версия языка в данном случае указана потому, что ею определяется количество разрядов, отводимых на переменные определенного типа. В данном случае на переменные типа integer отводится 16 бит, что определяет диапазон значений этого знакового типа от –32 768 до 32 767.
var a,i,n: integer;
for i := 2 to n do
При запуске этой программы для n = 7, 8 и 10 мы получим 5040, –25 216 и 24 320 соответственно. Первое полученное значение является верным, второе (отрицательное) может натолкнуть программиста на мысль, что в результате арифметических действий произошел выход за границу диапазона значений типа, а вот третье число само по себе может показаться верным, хотя, конечно, это не так.
На этом примере можно показать, что правильный алгоритм решения задачи при неправильном выборе типов данных может привести к абсурдному результату. И при разработке программы одним из важных этапов является оценка возможных значений (в том числе промежуточных) используемых переменных и выбор подходящих типов данных.
Следует подчеркнуть, что для целого типа выход за диапазон значений не приводит к прерыванию работы процессора (компьютер выдает неверные результаты), а для вещественных чисел (переполнение порядка) — это аварийная ситуация (floating point error), которая не пройдет незамеченной.
Шпаргалка Шпаргалка по "Базам Данных"
Билет 4. Трехзвенная модель распределения функций
AS -модель
Данная модель представляет собой систему, при которой каждая из трех функций приложения ( управление данными, обработка, представление) реализуется на отдельном компьютере.
Компонент, реализующий функции представления информации, взаимодействует с компонентом приложения как в модели DBS. Компонент приложения, расположенный на отдельном компьютере, связан с компонентом управления данными подобно модели RDA (см. вопрос 3).
Центральным звеном AS-модели является сервер приложения, на котором реализуется несколько прикладных функций, каждая из которых может быть предоставлена всем программам клиента. Серверов приложений может быть несколько, причем каждый из них предоставляет свой вид сервиса. Поступающие от клиентов к серверам запросы помещаются в очередь, из которой могут быть выбраны в соответствии с заданным приоритетом.
Компонент приложения, реализующий функции представления и являющийся клиентом для сервера приложения, может служить для организации интерфейса с конечным пользователем (т.е. обеспечивать прием данных от различных устройств или быть произвольной программой).
Достоинства: 1.гибкость и универсальность (за счет того, что различные функции реализованы на разных компьютерах); 2.- эффективность (за счет разделения функций).
Недостаток: высокие затраты ресурсов компьютера на обмен информацией.
Билет5.Транзакции. Восстановление транзакций
Транзакция
Под транзакцией понимается неделимая с точки зрения воздействия на БД последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации) такая, что либо результаты всех операторов, входящих в транзакцию, отображаются в БД, либо воздействие всех этих операторов полностью отсутствует. Лозунг транзакции - "Все или ничего": при завершении транзакции оператором COMMIT результаты гарантированно фиксируются во внешней памяти (смысл слова commit - "зафиксировать" результаты транзакции); при завершении транзакции оператором ROLLBACK результаты гарантированно отсутствуют во внешней памяти (смысл слова rollback - ликвидировать результаты транзакции).
Понятие транзакции имеет непосредственную связь с понятием целостности БД. Очень часто БД может обладать такими ограничениями целостности, которые просто невозможно не нарушить, выполняя только один оператор изменения БД. Пусть например существует 2 таблицы: Сотрудники и Отделы, причем в таблице отделы есть поле, хранящее число сотрудников в отделе. Надо принять на работу нового сотрудника. Для этого нужно выполнить 2 оператора: занести новую запись в таблицу сотрудники и изменить запись в таблице отделы. Либо мы сначала изменяем таблицу сотрудники, тогда таблица отделы некоторое время будет неверна, либо сначала изменяем таблицу отделы. В любом случае после выполнения только одного оператора бд будет находиться в противоречивом состоянии.
Поэтому для поддержания подобных ограничений целостности допускается их нарушение внутри транзакции с тем условием, чтобы к моменту завершения транзакции условия целостности были соблюдены. В системах с развитыми средствами ограничения и контроля целостности каждая транзакция начинается при целостном состоянии БД и должна оставить это состояние целостными после своего завершения. Несоблюдение этого условия приводит к тому, что вместо фиксации результатов транзакции происходит ее откат (т.е. вместо оператора COMMIT выполняется оператор ROLLBACK), и БД остается в таком состоянии, в котором находилась к моменту начала транзакции, т.е. в целостном состоянии.
Ни одна СУБД не обладает механизмами деления процесса обработки данных не отдельные транзакции, это должен делать прикладной программист с помощью операторов BEGIN TRANSACTION, COMMIT или ROLLBACK
Свойства транзакций:
-
Атомарность (все или ничего) – любая транзакция является неделимой единицей работы
Согласованность (непротиворечивость) – переводит бд из одного непротиворечивого состояния в другое
Изолированность – все транзакции выполняются независимо друг от друга, те промежуточные результаты незавершенной транзакции недоступны другим транзакциям
Продолжительность – результаты успешно завершенной транзакции сохраняются в бд и не могут быть утеряны при дальнейших сбоях
Из определения следует, что транзакции являются единицами восстановления в СУБД. Общими принципами восстановления являются следующие:
-
результаты зафиксированных транзакций должны быть сохранены (COMMIT) в восстановленном состоянии базы данных;
результаты незафиксированных транзакций должны отсутствовать (ROLLBACK) в восстановленном состоянии базы данных.
Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных:
-
Индивидуальный откат транзакции. Тривиальной ситуацией отката транзакции является ее явное завершение оператором ROLLBACK. Возможны также ситуации, когда откат транзакции инициируется системой. Примерами могут быть возникновение исключительной ситуации в прикладной программе (например, деление на ноль). Для восстановления согласованного состояния базы данных при индивидуальном откате транзакции нужно устранить последствия операторов модификации базы данных, которые выполнялись в этой транзакции.
Восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой). Такая ситуация может возникнуть при аварийном выключении электрического питания, при возникновении неустранимого сбоя процессора (например, срабатывании контроля оперативной памяти) и т.д. Ситуация характеризуется потерей той части базы данных, которая к моменту сбоя содержалась в буферах оперативной памяти.
Восстановление после поломки основного внешнего носителя базы данных (жесткий сбой). Эта ситуация при достаточно высокой надежности современных устройств внешней памяти может возникать сравнительно редко, но тем не менее, СУБД должна быть в состоянии восстановить базу данных даже и в этом случае. Основой восстановления является архивная копия и журнал изменений базы данных.
Возможны два основных варианта ведения журнальной информации. В первом варианте для каждой транзакции поддерживается отдельный локальный журнал изменений базы данных этой транзакцией. Эти локальные журналы используются для индивидуальных откатов транзакций и могут поддерживаться в оперативной памяти. Кроме того, поддерживается общий журнал изменений базы данных, используемый для восстановления состояния базы данных после мягких и жестких сбоев.
Этот подход позволяет быстро выполнять индивидуальные откаты транзакций, но приводит к дублированию информации в локальных и общем журналах. Поэтому чаще используется второй вариант - поддержание только общего журнала изменений базы данных, который используется и при выполнении индивидуальных откатов.
Билет 10. Модели распределенных баз данных. Однородные и неоднородные системы.
Однородные распределенные базы данных:
Однородная СУБД
| Типы РаБД | Однородность | Глобальная схема | Обеспечение интерфейса |
| 1) РаБД | + | + | Внутренние функции СУБД |
| 2) Мультибазы данных с глоб. схемой | - | + | Пользовательский интерфейс |
| 3) Федеративные БД | - | частичная | Пользовательский интерфейс |
| 4) Мультибазы данных (неодн-е) с общим языком доступа | - | функции языка доступа | Пользовательский интерфейс |
| 5) Однородные системы мультибаз данных | + | функции языка доступа | Пользовательский интерфейс + внутренние функции СУБД |
| 6) Интероперабельные системы | множество типов источников данных | отсутствие глобальной интеграции | реализация интерфейса средствами приложения |
Система мультибаз данных – это распределенная система, кот. служит внешним интерфейсом для доступа к множеству локальных СУБД или структурируется как глобальный уровень над локальными СУБД.
На уровне систем мультибаз данных добавляется неоднородность и по-прежнему используется глобальная схема. Как и в случае с однородными распределенными БД клиентские приложения оперируют с глобальной схемой, как с большой централизованной БД. Все отображения локальной БД и содержимое обрабатывается средствами глобального уровня. Однако в отличие от однородных распределенных БД мультибазы данных с глобальной схемой не обладают функциями СУБД, позволяющими поддерживать отображение и интерфейс между локальным и глобальным уровнем (в связи с неоднородностью). Использование глобальной схемы в концептуальном отношении выделить достаточно просто, но на практике связано с серьезными проблемами.
-
Глобальная схема должна содержать все данные
Все изменения в локальной БД должны распространяться на глобальную схему.
Клиентские приложения сами м.б. распределены на множество узлов. Это означает, что для осуществления какой-либо операции над локальной БД необходим доступ к глобальной схеме. В этом случае глобальная схема может быть централизована.
Федеративные БД в отличие от мультибаз не располагают полной глоб. схемой, к которой обращаются все приложения. Вместо этого поддерживается локальная схема импорта-экспорта данных. На каждом узле поддерживается частичная глоб. схема, описывающая информацию тех удаленных источников, данные с которых необходимы для выполнения бизнес функций на этом узле.
Недостатки:
-
Необходимо распространять изменения, производимые в глоб. схеме на соответствующие узлы.
Сложно определить, какие данные нужны на определенном узле.
Неоднородные системы мультибаз данных
Мультибазы с общим языком доступа фактически представляют собой распределенные среды управления с технологией Клиент-Сервер. В среде мультибаз данных с общим доступом (неоднор. или однор.) глобальная схема вообще отсутствует.
Интероперабельные - это системы, в которых сами приложения, выполняемые в среде той или иной СУБД, ответственны за интерфейсы между различными средами приложения, независимо от того, являются они однородными или неоднородными. Системы ориентированы главным образом на обмен данными. Дальнейшее развитие этих систем является объектно-ориентированные БД.
Принципы организации хранилища.
-
Проблемно предметная ориентация: данные объединяются в категории и хранятся и хранятся в соответствии с областями, которые они описывают, а не с приложениями, которые они используют.
Интегрированность: объединяет данные т.о., что бы они удовлетворяли всем требованиям всего предприятия, а не единственной функции бизнеса.
Некорректируемость: данные в хранилище данных не создаются, т.е. поступают из внешних источников, не корректируются, не удаляются.
Зависимость от времени: данные в хранилище точны и корректны только в том случае, когда они привязаны к некоторому промежутку или моменту времени.
-
извлечение – перемещение информации от источников данных в отдельную БД, приведение их к единому формату.
Преобразование – подготовка информации к хранению в оптимальной форме для реализации запроса, необходимого для принятия решений.
Анализ.
Представление.
-
Традиционные системы регистрации операций (БД)
Отдельные документы
Наборы данных
-
Территориальное и административное размещение.
Степень достоверности.
Частота обновляемости.
Система хранения и управления данными.
Задача словаря метаданных состоит в том, что бы освободить разработчика от необходимости стандартизировать источники данных.
Создание хранилищ данных не должно противоречить действующим системам сбора и обработки информации. Специальные компоненты словарей должны обеспечивать своевременное извлечение из словарей и обеспечить преобразование к единому формату на основе словаря метаданных.
Логическая структура данных хранилища данных отличается от структуры данных источников данных.
Для разработки эф-го процесса преобразования необходима хорошо проработанная модель корпоративных данных и модель технологии принятия решений.
Данные для пользователя удобно представлять в многоразмерных БД, где в качестве размерности могут выступать время, цена или географический регион.
Кроме извлечения данных из БД, принятия решений важен процесс извлечения знаний, в соответствии с информационными потребностями пользователя.
С т.з. пользователя в процессе извлечения знаний из БД должны решаться след. преобразования: данные ---- информация ---- знания ---- полученные решения.
Методы выявления и анализа знаний:
1.Ассоциация.
2. Последовательность – когда определяются сообщения связанные между собой во времени.
3.Классиффикация – выявление характеристик группы, к которой принадлежит объект.
4. Кластеризация – группы заранее не сформированы.
5. Прогнозирование – моделирование поведения определенного объекта на основе имеющихся знаний.
Средства извлечения знаний:
1. Нейронные сети. Пакеты, к. созданы для прогнозирования определенной области.
2. Деревья решений.
3. Индуктивное обучение.
4. Визуализация данных.
5 . Нечеткая логика.
6. Различные статистические методы.
Билет15.Характеристика ООБД.
Первым шагом к ОО подходу в области БД было создание структур, учитывающих специфику приложения и способных удерживать семантику информации.
В такой среде процесс программирования упрощается, а фундаментальная программа остается: поддерживающие реляционные средства управления данными и структурами данных, не способны поддерживать всю семантику, необходимую для приложения.
Эти проблемы связаны:
-
с типами данных.
операции не могут задать правила, необходимые для управления абстрактными типами данных.
Свойства ООБД:
1. Высокоэффективное представление, учитывающее особенности типов, через типы, методы, объекты.
2. Использование инкапсуляции.
3. Высокая степень непротиворечивости. Операции заданного объекта являются непротиворечивыми, независимо от того, какое приложение их вызывает. Для поддержания этой возможности средствами самих объектов, изменения могут быть сделаны только в объектах, а не в приложениях.
4. Снижение стоимости разработки новых приложений за счет повторного использования описания объектов, хранящихся в библиотеке классов.
Билет16.Манифест ООБД.
В манифесте ООБД (Atkinson et al., 1989) предлагаются обязательные характеристики, которым должна отвечать любая ООБД. Их выбор основан на 2 критериях: система должна быть объектно-ориентированной и представлять собой БД.
Три класса характеристик:
-
Обязательные.
Необязательные.
Открытые – позволяют пользователю выбирать свойства.
* Примечание. Уникальность работы указана на дату публикации, текущее значение может отличаться от указанного.
Читайте также:
- Какие шпоры сделать на огэ по биологии
- Жабий камень мазь инструкция отзывы для суставов
- Остеопороз на нервной почве
- Кта тестирование шпоры на казахском
- Секвестрированная грыжа диска l5-s1 что это такое у взрослого человека
 Пожалуйста, не занимайтесь самолечением!При симпотмах заболевания - обратитесь к врачу.
Пожалуйста, не занимайтесь самолечением!При симпотмах заболевания - обратитесь к врачу.